Web accessibility testing using local AI models to evaluate entire web pages
Originally shared on LinkedIn (opens in a new window), 2025-06-03.
Last week, I published a short article and a "watch Bob code" video demonstrating how to build your own automated accessibility testing tool as a Chrome extension. That finished with some AI generated tests that we could run within the tool. This week, I want to begin to extend the functionality of our tool to be able to test using AI, not just building the tool using it.
There are no changes to the GitHub code this week, but there is a new YouTube video: https://youtu.be/-bjSAPVd9zU
Motivation
Imagine being able to tell AI (Claude, ChatGPT, Gemini) to analyze an entire web page, or pages for accessibility issues and report on what is found? Even better if it can think beyond the regular automated testing we know and love from tools such as Deque System's Axe or TPGi's ARC tools, to utilize the strengths of different Large Language Models (LLMs) to consider the underlying page structure, the text of the page, the relative positioning of content. Hopefully those commercial tools will be doing that themselves very soon, if not to some extent already, but can we do this ourselves, and for free?
Free vs. Paid
We can already do some work with cloud-based AI in this area, the challenges are usually input context (modern web pages are large) and cost as both input and output tokens cost money. If we are dealing with large pages, that cost is not negligible.
The example I use in this week's video is inspecting a web page and asking what the dominant language of the text is, and if there are any non-dominant words or phrases in the text that do not have lang attributes (needed so that text-to-speech knows how to pronounce the words). Trying this query on Anthropic Claude Opus 4, the cost is approximately 58 cents US. That is one query for one test on one page. It is Anthropic's most capable and expensive model, and on Sonnet 4, the cost would be nearer 8 cents, though the analysis may not be so good. Even at 8 cents, Imagine scraping an entire corporate website of say, 6,000 pages (the approximate size of cnib.ca, my employer's); that's 8 x 6000 = 48,000 cents US = $480 US to test one WCAG guideline once for the site. With Opus, it would be $3,480 US for that one test. And it's actually a relatively small web page, real pages are often larger.
It's not that the paid AI tools like Claude are not good, they're unimaginably good, but the price for real work testing web pages is prohibitively expensive. We need free, or near free, tools to be able to test at the scale of real websites.
Free in this case means local AI running on our own servers, or even PCs and laptops. In this article, and the video, we run two different models locally on a small MacBook Air with 16GB of RAM, looking at the constraints that puts on us, and whether useful results are possible.
Ollama
The approach taken to running local AI is to use Ollama, a platform that allows for the installation of multiple LLM's locally on your machine, both with a command line interface to talk to the models, and running as a server with an API that can be used to interact remotely with the models. That API gives us the possibility of driving the AI from our Chrome automated testing extension. Ollama is available across Windows, Mac, and Linux so it is an approach that will work for all.
Models
In the video I play with two LLMs. One is Deepseek-R1 to demonstrate what this relatively famous "thinking" AI produces as output. The other is Llama 3.1 which was given the prompt used earlier to price the cost of testing with Claude.
There are three aspects to consider when choosing a local AI model:
- Minimum hardware requirements just to run
- The size of the input context window for passing in web pages to test
- The quality of the responses to prompts
Given that I use a small MacBook Air with 16GB of RAM, The hardware requirements immediately limit the models that I can run for demo purposes. As a compromise, I chose models that are around 5 GB in size in order to allow the laptop to still function well. And also to leave space for a large input context.
Context
Context (input plus output) affects the size of the web pages we can test, and some pages, usually those built on JavaScript frameworks can be remarkably large for the rendered content. I gave myself a context of 50,000 tokens to allow for large pages. That is really quite large. More common contexts for comparison would be:
- 2048 - Default for many models
- 4096 - Common extended context
- 8192 - Larger context for complex tasks
- 16384 - Very large context (if model supports it)
- 32768+ - Model-dependent maximum
So I chose even more than the 32K in that list, with a corresponding impact on performance of around 7 seconds to generate a single token. I chose this to simulate much larger pages than my test page, and also to ensure that token scarcity didn't impact on the quality of the responses. I wanted the best response to test queries I could get.
Wanting that high context constrained the available models. My Deepseek, for example, experiment was on a model that only provides up to an 8K context. When I tried to give that the source of my test web page, the head of the page got cropped (the newest content was kept).
For actual testing I needed to look at the available models and context sizes. Here are some for comparison:
- gemma2:27b - 8K context
- llama3.1:8b - 128K context
- qwen2.5:7b - 32K context
- mixtral:8x22b - 64K context
Of those, I chose llama3.1:8b to get a maximum of 128K context and a 5 GB model size.
Setting the context size
Just a short note on setting the context size for models. The actual context size we get with Ollama is dependent on available resources and just because a model can have 128K context doesn't mean you will get it on your hardware. To be sure what I was getting, I explicitly set my context to 50,000.
Confusingly there are two parameters related to context size: ctx_size and num_ctx
ctx_size is the maximum context window the model was trained to handle and is defined during model training and architecture definition and generally is not changeable, it is baked into the model weights. It defines the absolute maximum tokens the model can theoretically process.
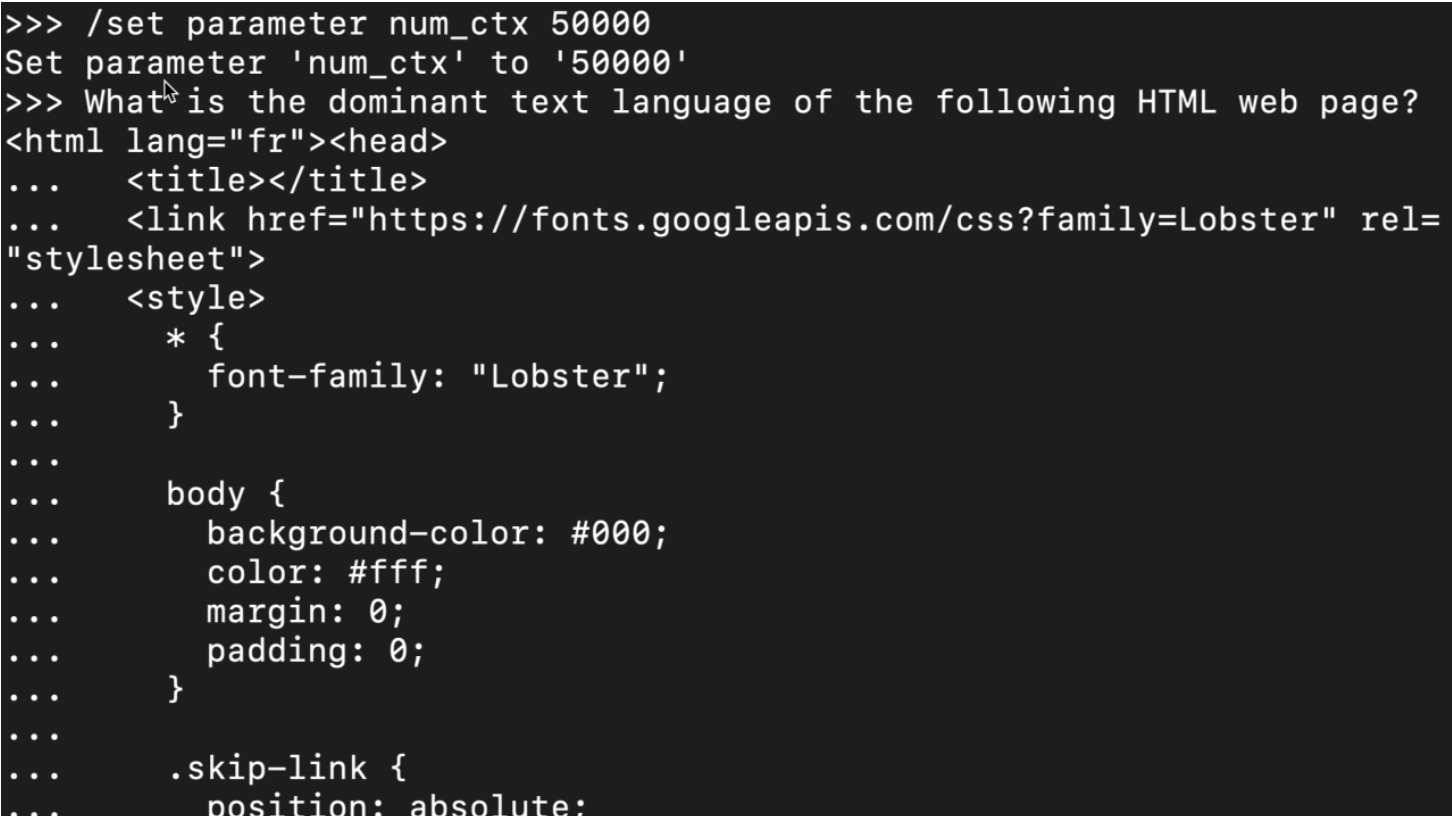
num_ctx is the actual context window you want to use during inference and is set at runtime when using the model. This is the command I give in the first line of the image at the top of this article where I set it to 50,000 before issuing my prompt. num_ctx may not be larger than ctx_size for your model. If you exceed that number you receive an error message from Ollama.
Quality of Response
I broke the prompt down into two parts. First I asked, "What is the dominant text language of the following HTML web page?" and pasted the source code of the rendered page immediately after the question mark. That source I got from Chrome dev tools by copying the <html> element at the top of the page (Chrome provides all of the contained content).
The (first) response from llama 3.1:8b:
The dominant text language of this HTML web page is English.
This can be determined by several factors:
- The
<lang>attribute in the<html>tag is set to "fr", which suggests that the page is intended for a French-speaking audience. However, upon examining the content of the page, it becomes clear that most of the text is written in English. - The majority of the links and text on the page are in English, with no signs of French language usage other than some titles and possibly some URLs.
- The HTML structure, including the use of elements like
<header>,<nav>, and<footer>, follows standard web development practices that are common in English-language websites.
Overall, while the <lang> attribute suggests a French audience, the content and design of the page indicate that it is primarily intended for an English-speaking audience. Therefore, I conclude that the dominant text language of this HTML web page is English.
Discussion on (first) response
The model correctly identified the body of the page text as English, even though as it noted, the lang attribute for the page was set to FR (French).
It justified the answer with three reasons: That most of the text is in English, that the majority of links and text on the page is in English, and the HTML structure and use of elements follow standard development practices in English-language websites. One wonders quite what the third reason alludes to, possibly that layout follows a left-to-right top-to-bottom layout.
The (second) response from llama 3.1:8b:
To the second prompt, "Are there any words or phrases not in the dominant language on the page, and are those words and phrases wrapped in a lang attribute to identify the language?" I received the following:
Yes, upon closer inspection, I notice that there are several words and phrases written in French (the non-dominant language) scattered throughout the page.
Examples include:
- "Español" (Spanish)
- "Français" (French)
- "Conditions génèrales" (French for "General Conditions")
- "×" (a "close" button with a Unicode character that is commonly used in French)
However, I also notice that some of these words and phrases are not wrapped in a lang attribute to identify the language. In fact, none of the non-English text on the page has a lang attribute.
This suggests that the author of the page may have intended to provide multilingual support, but did not properly implement it using HTML attributes like 'lang'.
Discussion on (second) response
Firstly, note the misspellings. These are real and in the test page specifically to be found by test software. The page has over 100 accessibility and design issues to find.
The words that the model found were in French and Spanish from the language switcher for the page. In total two words, one phrase, and one unicode character. That unicode character is being used on the page as a close icon on a dialog, which the model correctly identifies.
It also notes that they are not wrapped in lang attributes to inform text-to-speech tools how to pronounce them and will result in Screen-readers for example, pronouncing French and Spanish as if they are English words (generally called Franglais).
Note the final paragraph, where the model speculates on why the lang attribute was missing. A more detailed and precise prompt would instruct the model to avoid any speculation of this type.
Effectiveness of the Testing
The llama 3.1:8b model did very well. It correctly identified the language attribute in the <html> element as identifying a different language compared to the dominant language of the page, and also identified words, phrases and characters not in the dominant language, and noted that those words did not have lang attributes assigned.
In terms of WCAG, we tested
- 3.1.1 Language of page (level A)
- 3.1.2 Language of parts (level AA)
- 4.1.2 Name, Role, Value (level A)
Language of page is checking we do have a declared language. This is what existing commercial test tools test for.
Language of parts, identifying non-dominant words that do not have a language attribute, is something that is currently only done manually during page inspection (perhaps there are tools I've not tried?) That automation is novel.
Name, Role, Value is from identifying that the declared language is of the wrong value. Again this is not normally found by existing commercial tools.
This was one simple test of one page, and it needs to be followed up by more rigorous testing and verification, but we do seem to have achieved the original goal of reaching beyond existing commercial testing. It appears to be a valid approach.
The Correct Solution to the Problem?
In the short term, the answer would seem to be yes, we can easily provide a prompt to identify language issues, but it does come at the expense of power-hungry, resource hungry AI. On a regular 16 GB laptop, the first of the two prompts took 24 minutes to complete.
We also have unknowns in this work, we don't actually know how many languages the AI model can detect, or how reliably, this was one simple test, and a great deal more inspection and research are needed to know the constraints of the test. On the other hand, no-one is going to manually inspect 6,000 pages of content for foreign words, so every word or phrase with no language attribute that is found, is one more accessibility issue caught. Even if we don't find all 3.1.2 issues on a website, we will have done better than a regular web audit if the issue was not on one of the (usually few) manually inspected pages.
Next Steps
This week my video was simply exploring the setup and usefulness of local AI in automated testing. Now that we have an implementation that works, we need to try connecting to the Ollama server from our Chrome extension and reporting issues found through AI. That will be part 3 of the video series.