Accessibility tools and AI code repair make the same mistake — and share a common fix
Originally shared on LinkedIn (opens in a new window), 2026-06-11.
Like almost everything published online, my work has been read by GPTBot. I found it in my server logs, and it has been to most of the places I've ever published — papers, talks, code, this profile. That's where we are now. So I asked it the obvious question: what had it made of the work?
The bot answered confidently, but it was wrong about one thing in a specific and revealing way. It described my research, and current work, as working with a static code analyser: read the source, check it against a list of accessibility rules, report the violations. Accessibility as a checklist you run over code.
It's not what that work is, and I've had to re-write part of this website to provide a clearer explanation for the bots, and for us humans. That's on me.
But that honest mistake by GPTBot is the interesting part, because more generally it's the same mistake, away from my work, almost every accessibility tool also makes, and the same one the current wave of AI code-repair tools makes too. It had read the field's research and reached for the field's own default stance.
Three places the accessibility tools can go quiet
None of these is exotic. Each one can pass the linters, the scanners, and an AI code review, and routinely does, and each one breaks for a real person, for a different reason.
The Escape key. A modal or a popup should close on Escape. But the handler for Escape is very often global; bound to the document, not to the element it affects. A linter reading the component seldom notices it: it is looking at the modal dialog while the behaviour lives on document. The element looks fine while correctness lives at the page level, where element-scoped tools are not looking.
Page timers. Session, security, and idle timers, the ones that log you out, refresh the view, or move focus out from under you, run in JavaScript, and they are usually not in an explicit <script> you can eyeball. They arrive through a library, several dependencies deep. A rendered-DOM scanner never sees them; a source reader sees them only if it follows the code into what it imports. The behaviour most likely to derail a screen-reader user is the behaviour least visible in the artefact.
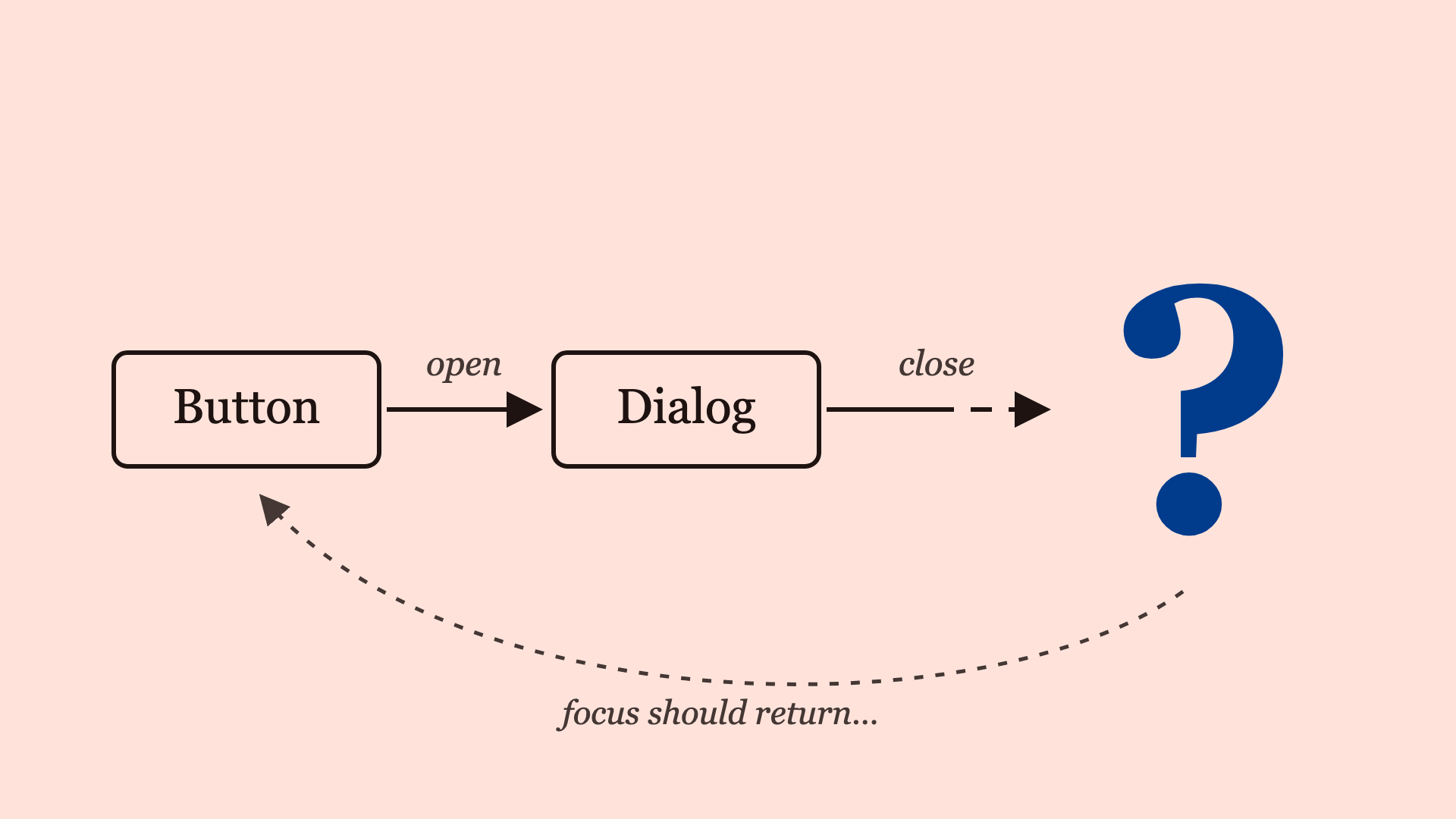
Focus, on open and on close. When a modal opens, does focus move into it? Tools increasingly check that much. The harder, more-missed question is what happens when it closes: does focus return to the control that opened it, land at the top of the page, or go nowhere at all? That is not a property of any single element. It is a property of a sequence of states — open, interact, close — and you can only check it if you can reason about the sequence, not the snapshot.
In each case the tools — generally, at least — look at the artefact: the markup, the source text, the rendered tree. And the failure lives where the artefact does not show it: in a global handler, inside a dependency, across a sequence of states. That is the blind spot.
The shared mistake
It's worth stating plainly, because it hides behind very different-looking tools. Accessibility linters read a file and check whether the right things are present. Rendered-DOM scanners read the page after JavaScript has run and check whether the right things ended up in the tree. AI code-repair tools read the source as text and rewrite it into something that looks more correct. All three treat the artefact — the code, the markup, the DOM — as the thing to inspect or fix.
But the artefact isn't the thing. It's a projection of the thing. The thing is the behaviour: the states a user can reach, the transitions available to them, the announcements that fire, the focus that moves or doesn't. Accessibility is a property of that behaviour, not of the text that happens to produce it.
The inversion
So here is the claim the whole argument turns on:
Source code is a projection of an executable model of behaviour and design intent. Accessibility is a property you verify against that whole model — not a checklist you apply to parts of the code.
Change the question and everything downstream changes. Stop asking is this ARIA attribute present? and start asking can a user ever reach a state where focus is trapped, a required announcement never fires, or a control becomes unreachable? The first is a lint. The second is verification — the posture safety-critical engineering has taken for decades, because "it looks right" was never good enough there.
This isn't a new idea; it's an idea from my doctoral work, nearly twenty years old. My doctoral work built an executable model of interface behaviour — actions, states, transitions — as a first-class artefact, with the accessibility model mapped onto it. It is that model that is rendered as the application or website. I parked it when I joined CNIB. What's changed in that time isn't the model. What's changed is that reasoning about behaviour from real source (and keeping a model and code in step) used to be considered too expensive and cumbersome to be practical — and that is exactly the kind of translation work modern AI is good at.
Where my model meets AI code repair
This is where the two halves meet. The deepest weakness of AI code repair is that it operates on text with nothing to check itself against. It generates a fix that reads well and hands it over. Was it correct? Did it break something else? The model can't say, because there's no ground truth, no bigger picture — only more plausible text. The careful objection is that real repair pipelines verify against test suites — and they do. But look at what the tests cover. Functional behaviour, sometimes thoroughly. Accessibility behaviour — where focus lands, what gets announced, what Escape does — almost never. For the thing we're discussing, the oracle, the understanding of design intent, doesn't usually exist. That's why "AI fixed your accessibility" should make you nervous: an unverifiable fix to an accessibility problem is its own kind of harm.
A behavioural model is the missing ground truth. With one, remediation stops being rewrite the text and hope and becomes transform the model, then re-verify the behaviour. The fix is checkable; there's a traceable line from the requirement, through the model, to the behaviour that changed. That isn't AI replacing engineering judgement — it's AI doing the flexible translation while a formal model does the verifying, each doing what it is actually good at.
Remediation is a loop, not a step
But a model doesn't make remediation perfect, and this is the part the optimistic version always skips. Real systems are complex. Fixing one thing moves another. A remediation — to source or to a model — routinely introduces its own artefacts and faults. One pass is never enough, and anyone who tells you that it is, is probably selling something.
So the real shape isn't a fix; it's a loop: populate the model from the information we have, re-populate it to best practice, then test the result — and fix the problems the remediation itself created. Repeat until nothing improves. Then, and this is the important part, report honestly what you did and didn't achieve. And then project the updated code.
I'm not speculating about this loop. I run a version of it now, in my PDF work: it takes a document, builds a structural model, rebuilds it accessibly against best-practice rules, re-audits the result, fixes the artefacts the rebuild introduced, and iterates until it converges — then issues an honest report of what was fixed, what couldn't be, and at what confidence. And the re-audit is, as far as possible, deterministic rule-checking — not the same AI marking its own work.
The loop itself is domain-independent — build, verify, fix, report is engineering discipline, not a property of documents. What is domain-specific is the lift and the checkers, which is where the honesty has to live.
The honest crux: the lift
The PDF work is also where I'd warn you off the easy version of this argument — the one where the model is clean and only the legacy web is messy. The hard part, in every domain, is the lift: recovering a faithful model from the source artefact in the first place. In my PDF work that artefact might be a document from 1951, scanned — sometimes badly — in an arbitrary layout, dense with the things that break automated structure recovery: mathematics, charts, tables. And a raster scan has no structure to recover at all: I start from coloured dots. Every heading, every table cell, every formula has to be inferred from pixels — I rely on Vision AI to construct the very model I then test against. The web lift is hard differently: its artefact is at least semi-structured — elements, attributes, a DOM — but the behaviour is scattered across code, dependencies, and time. The lift is real everywhere, and it is fallible everywhere.
If the lift is wrong, the model you verified is faithful to nothing. And the moment you let AI do the lift — which you must, because hand-building these models is the cost that sank this whole approach twenty years ago — you reintroduce uncertainty at the very bottom of the stack. There is no version of this where the lift is guaranteed.
This is where it would be easy to oversell the loop, so let me be careful about what it does and doesn't buy. The loop and the honest report guard against drift: they stop the lift and the remediation from quietly degrading the page, and they tell the truth about the residue. What they do not do — what nothing yet does — is guarantee that the remediated page is equivalent to what its designer intended.
Because the lift's deepest problem isn't accuracy; it's reification. Code is a scattered and imperfect reification of design intent. Between the idea of how an interface should behave and the code that realises it, information is lost — and no lift can recover intent the code never captured. Reverse-engineering a model from source recovers what was reified, not what was meant; missing information stays missing.
This is exactly why CISNA — the modelling framework from that doctoral work — exists: to describe the model of intent precisely, as a first-class thing, instead of leaving it implicit in code that may never have held it. With that model you have a reference to verify against. Lifting from legacy code, you don't — you have an imperfect reification, and a best-effort recovery of it.
The piece still missing, the part we are honestly not yet at, is a final stage that tests for equivalent representation and behaviour between the original intent and the remediated and adapted result, allowing for the corrections deliberately made along the way. Until that exists, the claim stays bounded: the loop holds the line against drift; equivalence to intent is still ahead of us. That frontier is the real prize: knowing we have a fully accessible application or website that matches all of the original design intent.
What this does not solve
None of this solves accessibility, and I want to be precise about why. A model can verify behaviour — focus, state, reachability, the firing of announcements — the mechanical floor. It cannot tell you whether your alt text means anything, whether your language is plain enough, whether the cognitive load is humane, whether the experience is dignified. Those aren't model-checkable and never will be. They are judgements, and they belong to people — ideally to disabled people testing the real thing. I build lived-experience testing tools precisely because that work doesn't go away. If anything, clearing the mechanical floor by machine is what frees human attention to go where it actually counts.
The same fix for both
So: the AI that's read the field thought accessibility is a checklist that you run over code. Most of our tools agree with it. The current generation of code-repair AI makes the same assumption from the other end, and inherits the same problem — it can't verify when there is no model to verify against (bar inferring a model from what is available to it).
Someone will say this is just an overlay with a PhD. I'll take that — because an overlay promises two things, and both can only be kept at the other end of the pipeline. The first promise is remediation: fixing what is broken. That has to happen at the source, informed by design intent, before the page is ever served.
The second promise is the one that has always interested me more: adaptation — reshaping an interface to meet the needs and preferences of a particular user, by adapting the behavioural model. That is what user capability modelling is for, and was a large part of my PhD. Once a behaviour model is populated and carries the design intent, you can then adapt that population to a user's needs and project an interface that fits them — the same machinery, pointed at a person. Overlays attempt both against the rendered result: reified code, stripped of intent, UX decisions already burnt in, at the last moment in the pipeline. Too late to execute either promise well, if at all.
The fix is the same for both. Stop treating the code as the thing. Build that model of the executable behaviour that can be reviewed, tested, simulated; verify against that, remediate in a loop, and report honestly what's left, and then project the executable code.
The future of AI in accessibility isn't a tool that rewrites your code and tells you you're compliant. It's a tool that supports proper understanding of the design and its impact on users, supports remediation and adaptation of the design, that's honest about what it changed, what it couldn't, and what still needs a human.